Demo page
AdvSV: An Over-the-Air Adversarial Attack Dataset for Speaker Verification
If you'd like to access this dataset, Please fill in the form. We'll promptly review and respond. Thank you for your
support.
If you want to know about AdvSV's build process, catalogue structure, baseline model, etc., please visit https://github.com/AdvSV/AdvSV.github.io
Abstract
Automatic Speaker Verification (ASV) displays strong performance under controlled conditions. Yet, current studies highlight the dangers posed by technologies like Text-to-Speech (TTS) and Voice Conversion (VC). These expose vulnerabilities in ASV systems during attack scenarios. However, the lack of benchmark datasets for adversarial attacks limits effective countermeasure assessment. Dataset differences, such as between VCTK and Voxceleb1, add complexity to performance evaluations. To tackle these issues, this paper introduces the AdvSV dataset, built upon the Voxceleb1 Verification test set. The dataset includes the latest ASV victim model, PGD-generated adversarial samples, and recorded replay attacks. This comprehensive resource provides valuable insights to enhance ASV system robustness against adversarial attacks and replay threats.
Overview
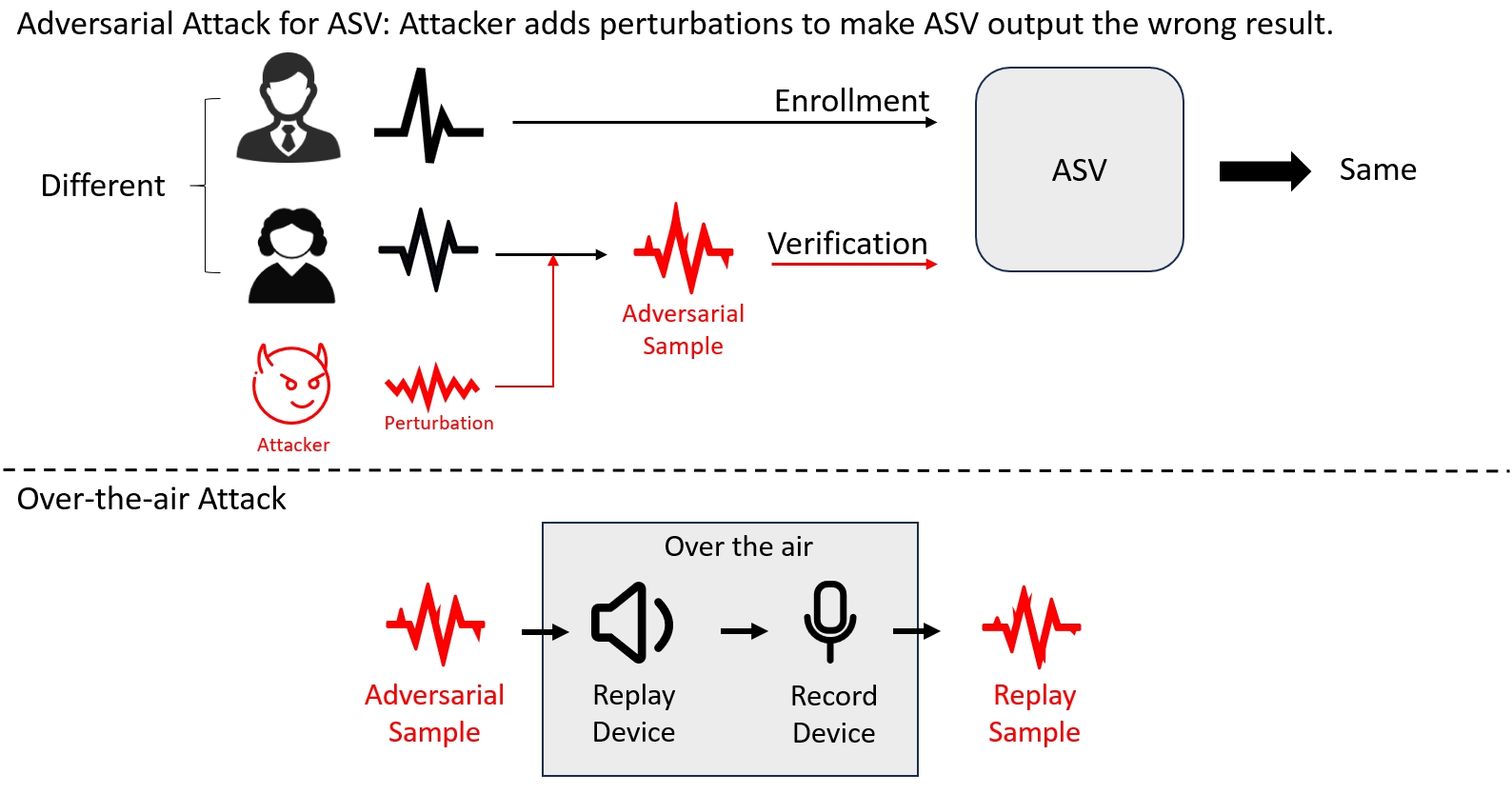
Demo Samples
| Enrollment File | Test File | Enrollment Audio | Test Audio |
|---|---|---|---|
| id10270/5r0dWxy17C8/00001 | id10292/gm6PJowclv0/00027 |
Demo-based PGD Attack and Replay Samples
| Speaker | Recorder | RawNet3 | ECAPATDNN | ResNetSE34V2 | XVector |
|---|---|---|---|---|---|
| NA | NA | ||||
| High | iOS | ||||
| High | Android-High | ||||
| High | Android-Low | ||||
| Medium | iOS | ||||
| Medium | Android-High | ||||
| Medium | Android-Low | ||||
| Low | iOS | ||||
| Low | Android-High | ||||
| Low | Android-Low |
Demo-based Ensemble PGD Attack and Replay Samples
| Speaker | Recorder | w/o RawNet3 | w/o ECAPATDNN | w/o ResNetSE34V2 | w/o XVector |
|---|---|---|---|---|---|
| NA | NA | ||||
| High | iOS | ||||
| High | Android-High | ||||
| High | Android-Low | ||||
| Medium | iOS | ||||
| Medium | Android-High | ||||
| Medium | Android-Low | ||||
| Low | iOS | ||||
| Low | Android-High | ||||
| Low | Android-Low |